
Quantum CFD on Real Hardware: From Linear Transport to Nonlinear Flow Around Obstacles

How a new quantum lattice Boltzmann algorithm and Haiqu's execution stack produced the first nonlinear Navier-Stokes flow with geometry on a quantum processor: a technical perspective from Haiqu on the Quanscient–Haiqu paper (arXiv:2603.02127, March 2026).
The invisible simulations behind everyday engineering
Every time an aircraft wing is shaped, a car body is profiled, or a gas turbine is optimized, the design passes through computational fluid dynamics (CFD) simulation. These simulations solve the equations governing how fluids move: where pressure builds, where flow separates, where turbulence forms. CFD is one of the most compute-intensive workloads in industrial engineering. A full-fidelity aeroacoustic simulation of a commercial aircraft can require billions of mesh points and weeks on the largest supercomputer clusters. Even with extraordinary classical HPC progress, many problems in turbulence, multiphase flow, and coupled multiphysics remain intractable at the resolutions engineers actually need.
Quantum computing enters the CFD conversation because of a structural advantage: a quantum computer can represent spatial grids whose size is exponential in the number of qubits, potentially enabling simulations at scales inaccessible to classical machines. Realizing that potential requires overcoming significant technical challenges, and the field's credibility depends on demonstrating progress on the right kind of problems.

Why the lattice Boltzmann method suits quantum computing
The lattice Boltzmann method (LBM) models fluid dynamics not by solving the Navier-Stokes equations directly, but by evolving mesoscopic particle distributions on a discrete lattice through two local operations — collision and streaming — from which macroscopic quantities such as fluid pressure and velocity emerge. This structure is already massively parallel on classical hardware; landmark LBM simulations have reached trillions of lattice cells on GPU clusters.
The same structure maps naturally to quantum algorithms, forming the quantum lattice Boltzmann method (QLBM). Streaming becomes a quantum walk. Collision is local and independent of lattice size. And the heavy memory requirements that bottleneck classical LBM become a non-issue when the grid is encoded logarithmically in qubits.
So far, the complete record of QLBM on actual quantum processors — including our own earlier work with Quanscient on IonQ Aria (2024, the largest QLBM grid demonstrated on hardware) — has been limited to linear dynamics on 1D, 2D, and 3D grids. No obstacles. No boundaries beyond periodic conditions. No coupled velocity fields. Each result was an important milestone but the physics that makes real CFD hard was entirely absent from the hardware record.
Until now.

What does this paper demonstrate?
Our joint paper with Quanscientr introduces a new quantum algorithm for the lattice Boltzmann method based on the one-step simplified LBM (OSSLBM) and validates it across several cases, culminating in a nonlinear laminar flow benchmark on real quantum hardware.
The benchmark: a D2Q9 lattice on an 8×8 grid with a 2×2 immersed square obstacle, inlet-outlet boundary conditions, and zero Dirichlet walls. Flow is driven by a fixed inlet velocity, deflects around the obstacle, and evolves through a 15-step hybrid quantum-classical loop on IBM's ibm_boston processor (Heron R3, 156 qubits).
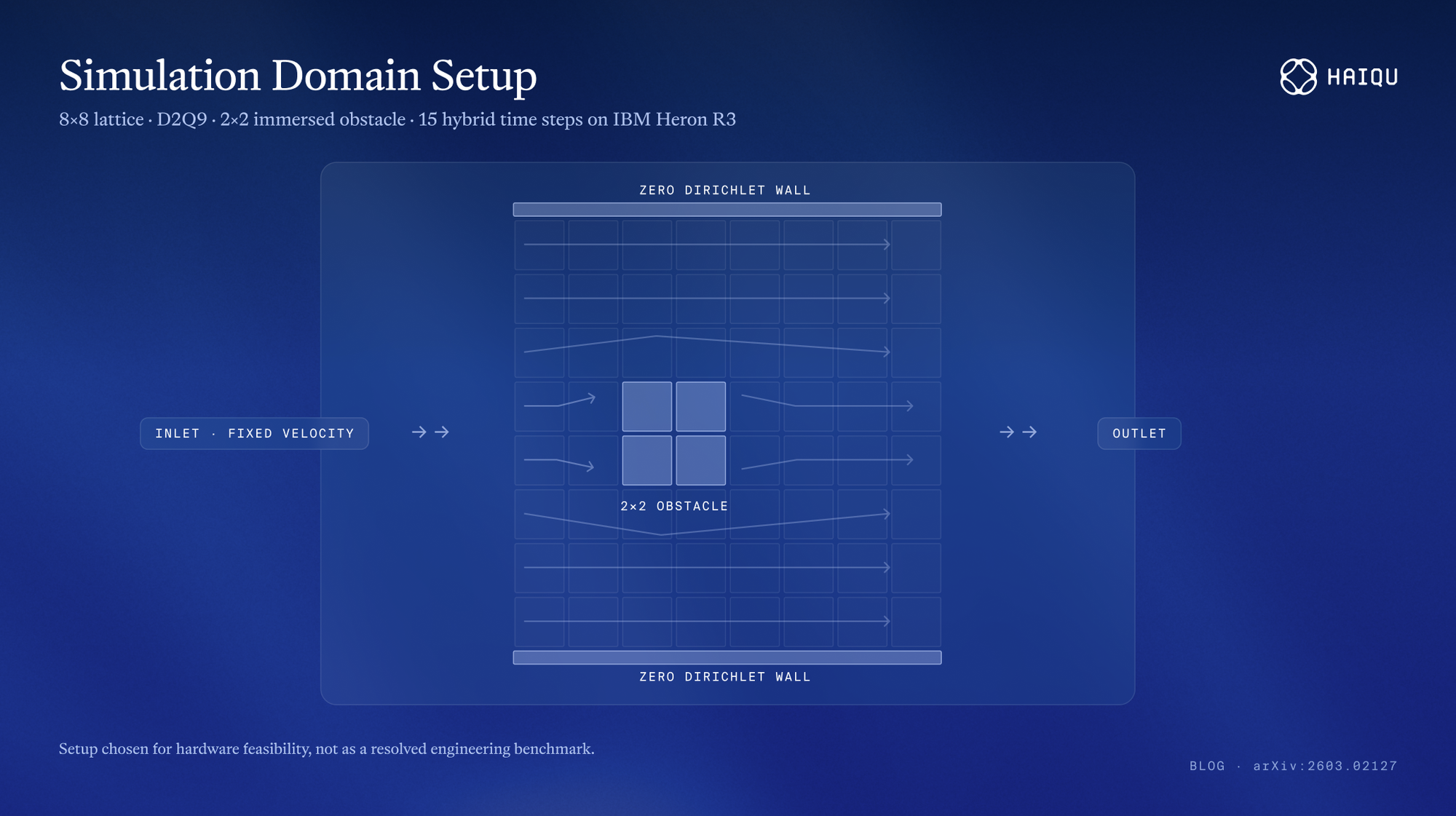
Three features distinguish this from all prior QLBM hardware demonstrations.
Nonlinear Navier-Stokes physics. The incompressible Navier-Stokes equations govern the evolution. The nonlinear equilibrium terms are recomputed classically at each step and re-encoded into the quantum state; the quantum processor handles the structured linear update. This hybrid strategy keeps circuits shallow enough for current hardware while accommodating physics that cannot be implemented unitarily.
An immersed obstacle with boundary conditions. No prior QLBM hardware run included any internal geometry. The boundary treatment uses multi-controlled gates that are backpropagated and applied classically to the measured bitstrings — substantially reducing circuit depth.
Coupled full-field recovery over 15 time steps. The experiment recovers density and both velocity components (ρ, u_x, u_y) at each step, with the mean squared error relative to a steady-state reference decreasing over the evolution. While a steady state is not reached within the 15 steps executed on the quanutm device, the results show a convergence towards it.

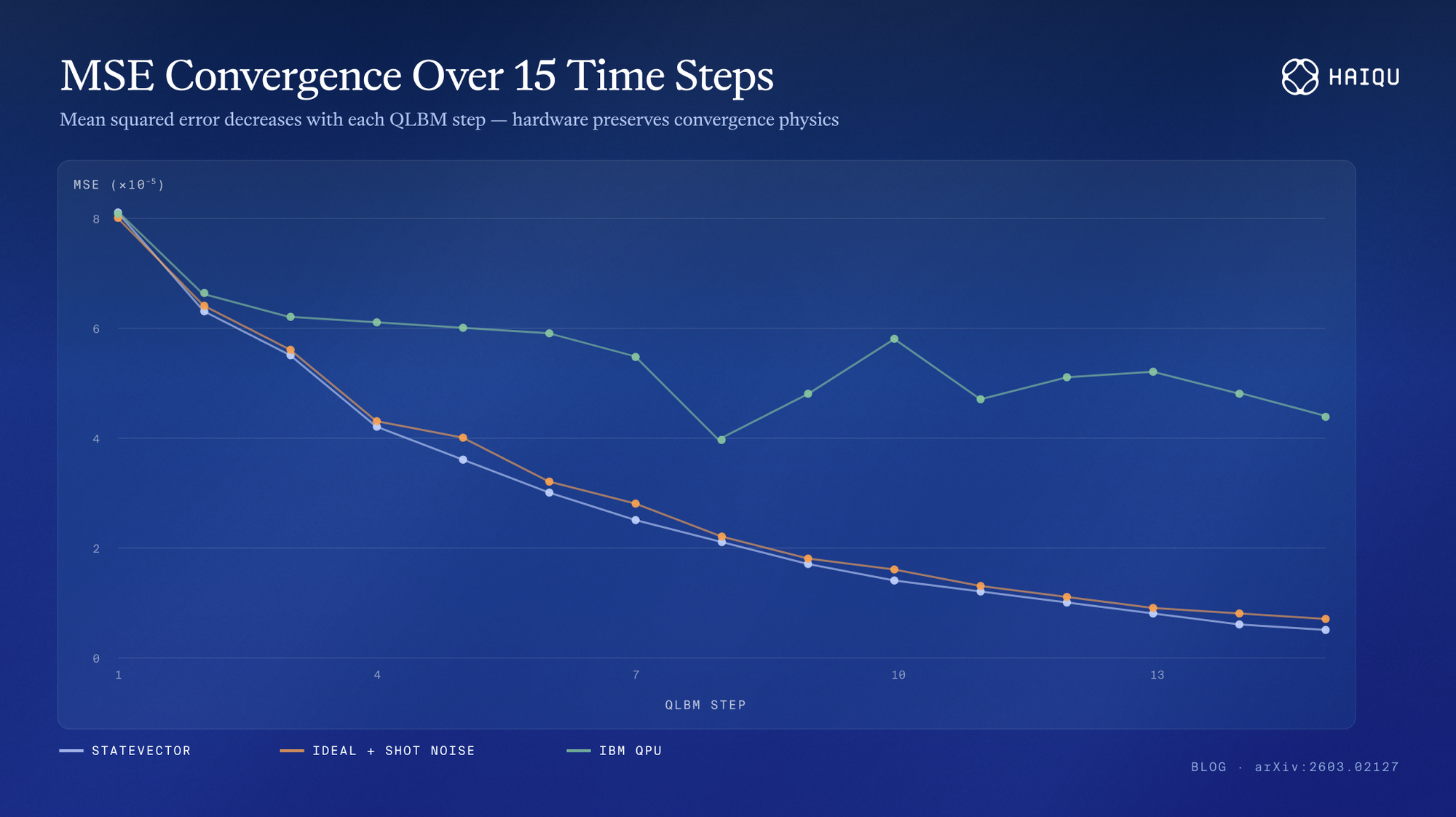
Left: Ideal vs. hardware field maps after 15 time steps for ρ, u_x, u_y Right: MSE convergence plot (statevector, ideal + shot noise, IBM QPU). The IBM QPU execution is noisier but continues to reduce error with subsequent steps — evidence that hardware preserves the convergence physics.
The algorithmic advance: OSSLBM
Our paper's contribution extends beyond the hardware benchmark. Traditional QLBM approaches treat collision and streaming as separate operations on distribution functions. The OSSLBM restructures this into a single-step update operating on macroscopic fields: density, velocity, and pressure, with distribution functions appearing only in the propagation subroutine.
This gives OSSLBM more flexibility to accommodate different physics (acoustics, diffusion, nonlinear Navier-Stokes) within one framework, while keeping the core gate and qubit complexity efficient. For linear problems, it supports multi-step evolution without intermediate measurement — a prerequisite for any future quantum advantage.
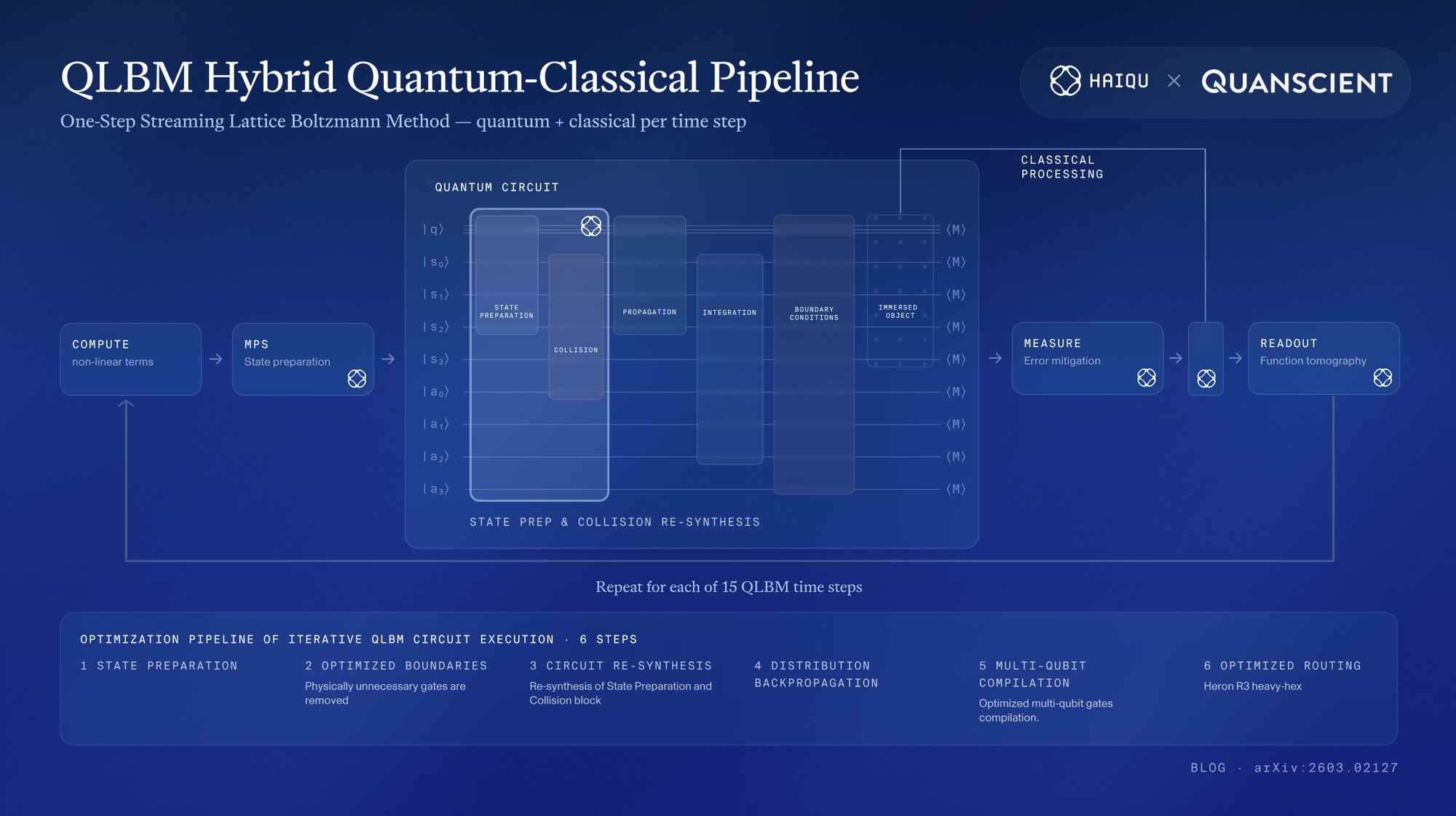
Making it run: Haiqu's hardware-enabling stack
A well-designed quantum algorithm is one thing. Getting it to run on hardware is another. Haiqu closed the engineering gap and enabled on-hardware execution thanks to the compilation, state preparation, tomography, and noise-mitigation stack that made the nonlinear obstacle benchmark practical on IBM's superconducting hardware.
The compilation challenge was substantial. A direct, unoptimized implementation produces approximately 1,825 two-qubit gates after transpilation to the Heron R3 heavy-hex connectivity. This is far beyond what today's error rates allow to execute accurately enough. Haiqu's optimization pipeline brought this down to around 540 two-qubit gates through several coordinated approaches.

Several techniques contributed to the reduction. The QLBM collision step was combined with initial state preparation, strongly compressing the circuit at the cost of only two extra qubits. The state preparation itself was optimized to take advantage of QPU's near-linear qubit layout. Furthermore, commutation of circuit parts implementing boundaries and obstacles with the final measurement was exploited to offload some computation to classical post-processing, shortening the circuit. Finally, all gate sequences were compressed using optimized decompositions of multi-qubit operations.
Noise mitigation was equally important. The execution combined several standard techniques like dynamical decoupling to protect idle qubits, Pauli twirling to symmetrize noise, and operator decoherence renormalization to correct the recovered field norms. With only 3–6% of the 30,000 shots per step surviving post-selection, induced by the QLBM unitary construction, the usable data for field reconstruction was thin. At these margins, every compilation and mitigation choice matters directly.
Finally, recovering full flow fields is required on each step as a part of QLBM’s hybrid pipeline, which is a major bottleneck, since standard tomography has prohibited scaling. We developed a novel variational function tomography method, allowing us to recover near-ideal field values with only a handful of shots. Previous demonstrations were focused on toy examples, where solutions are trivial and known, hence the readout problem did not arise. On the contrary, we demonstrated the most complex readout so far in the quantum CFD, applied to realistic flows.
This is an essential part of a realistic quantum computing workflow. The middleware layer: compilation, transpilation, error mitigation, readout, and runtime orchestration, determines whether a given algorithm produces meaningful results on a given hardware.
Honest scope: what this does and does not show
This paper demonstrates that QLBM can encode, evolve, and reconstruct a nonlinear Navier-Stokes flow field with an internal obstacle on a real quantum processor, preserving qualitative physics across 15 time steps. That is a material advance over every prior QLBM hardware run.
Whether QLBM can move to deeper end-to-end evolution remains open, depending on both hardware progress and fundamental algorithmic constraints.
The honest framing: this is the most physically complex QLBM simulation run on a real quantum processor in the public record. The advance is in the class of problems, not the immediate scale. The distance between that breakthrough and practical engineering application is still significant. But it is shrinking specifically in the areas where middleware investment pays off: compilation, noise mitigation, and orchestration.
Why should the industry pay attention now?
For R&D leaders in aerospace, automotive, and energy, the significance is strategic rather than operational.
Turbulence alone scales as O(Re³) with the Reynolds number; full-scale aircraft simulations at Re ~ 10⁸ imply roughly 10²⁴ floating-point operations. Quantum computing is one of the very few plausible paths to fundamentally different scaling for these workloads. But that path's credibility depends on the field solving the right kind of problems, not just bigger grids for linear transport.
These results are important because they demonstrate QLBM on real quantum processors, moving toward the very features that make real CFD hard: obstacles, boundaries, coupled fields, and nonlinear dynamics. The grid size is still very small, but the problem difficulty is a qualitative leap.
From Haiqu's perspective, the paper validates a thesis we have held from the start: the path to practical quantum scientific computing runs through the execution layer. Better qubits and better algorithms are both necessary but not sufficient. Getting real physics onto real hardware requires an optimization and runtime stack that adapts to the realities of current devices. We will continue building that stack, and we look forward to the experiments it enables next.
The paper "Quantum Algorithm for the Lattice Boltzmann Method with Applications on Real Quantum Devices" by Bastida-Zamora, Budinski, Kerppo, Lahtinen, Niemimäki, Steadman, Zamora-Zamora, Sagaut, Bohun, Koch-Janusz, and Lukin is available at arXiv:2603.02127.